
La semana pasada los artistas de Deepmind volvían a sorprender con una nueva versión de AlphaGo, la Zero. Este nuevo ingenio es capaz de aprender a jugar desde cero, logrando superar a la versión anterior tras 21 días de auto-entrenamiento.
Desde el punto de vista técnico son muchas las novedades. En las versiones anteriores el sistema se basaba en 3 elementos: 1. una red neuronal que predice el siguiente movimiento, que incluía mucho contexto específico del juego (p.ej. si estaba en atari); 2.- otra red neuronal que evaluaba la posición global; y 3.- simulación de montecarlo para simular miles de partidas y evaluar si una jugada es efectiva. En la nueva versión Zero, estos elementos son más «puros»: las 2 redes neuronales acaban siendo 1 sola, sin input de contexto específico (solo si se está en ko); y montecarlo se usa mucho menos.
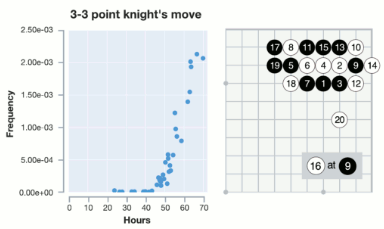 Sorprende también ver que durante el aprendizaje va encontrando fusekis y josekis, y usando un histograma se puede ver si los sigue usando a medida que mejora o lo deja de usar. Esto es, si un joseki es suficientemente correcto.
Sorprende también ver que durante el aprendizaje va encontrando fusekis y josekis, y usando un histograma se puede ver si los sigue usando a medida que mejora o lo deja de usar. Esto es, si un joseki es suficientemente correcto.
Por ejemplo esta imagen muestra las veces que aparece el joseki durante el paso de horas de entrenamiento, hasta 70 horas (equivalente al AlphaGo Lee, el que ganó a Lee Sedol). El paper original muestra otros ejemplos en el anexo, por ejemplo la absurda jugada de jugar en el 1-1 aparece hasta las 20 horas de entrenamiento.
 Deepmind, tras el triunfo de AlphaGo contra Lee Sedol afirmó que cerraba el proyecto. Meses después aparece con Master y más tarde con el evento en China donde gana a Ke Jie. De nuevo dijeron que ya no habrían más noticias. De nuevo sorprenden.
Deepmind, tras el triunfo de AlphaGo contra Lee Sedol afirmó que cerraba el proyecto. Meses después aparece con Master y más tarde con el evento en China donde gana a Ke Jie. De nuevo dijeron que ya no habrían más noticias. De nuevo sorprenden.
Uno de los puntos remarcables de esta nueva versión es su bajo consumo de potencia de proceso, de hecho, un orden de magnitud menor. El entrenamiento se hizo con solo 4 TPU (GPUs específicas de Google).
Por otro lado, hay que recordar que entrenar una red neuronal requiere muchísima más potencia computacional que usarla. Esto es, jugar miles de partidas para afinar cada peso individual de cada conexión neuronal es muy costoso; pero con esos pesos optimizados y fijos, jugar una partida sencilla ya no requiere gran coste.
Teniendo en cuenta esto último, me pregunto si podría llegar a funcionar con un PC comercial, amplificado con algunas GPUs de tarjetas gráficas modernas; o con el sistema en cloud de Google con una cuota asumible por un aficionado.
¿Cuál será la siguiente sorpresa de Deepmind?